BIURO FRANCJA
Agent IA de Qualification des Prospects
Comment l'intelligence artificielle transforme la prospection B2B export
Pologne → France — Scoring automatique, routing intelligent, action immédiate.
Pitch Deck — 30/06/2026
CONFIDENTIEL
Contexte & Problème
Pourquoi un agent IA pour qualifier les prospects ?
01
Qualification manuelle
Chaque lead analysé à la main : secteur, taille, email — 20 minutes par prospect minimum. Processus non viable avec du volume croissant.
02
Conversion faible
Sans scoring objectif, impossible de prioriser. Temps perdu sur des prospects non qualifiés au détriment des leads à fort potentiel.
03
Marché complexe
L'export Pologne → France demande une expertise sectorielle pointue. Secteur, taille et maturité varient considérablement.
Biuro Francja reçoit des demandes de PME polonaises souhaitant exporter vers la France. Sans outil de scoring, impossible de savoir qui appeler en premier. Objectif : qualifier et router chaque lead en moins de 30 secondes.
Biuro Francja · Agent IA · Confidentiel2 / 12
La Solution
Un agent IA end-to-end — sans scraping, axé sur les données formulaire
Collecte automatique
Formulaire Tally déclenche un Webhook n8n. Données reçues en temps réel : nom, email, site, secteur, taille. Parsing robuste par label avec fallback.
Scoring IA
GPT-4.1-mini analyse 3 critères calibrés : Market Fit (secteur), Company Size (taille), Email professionnel. Prompt expert Biuro Francja avec barème strict.
Routing intelligent
Score 0-65 → classification Tier A/B/C. Routing automatique : HOT → appel + email, WARM → nurture, COLD → log uniquement.
Action automatisée
Email personnalisé au prospect + alerte interne avec score détaillé, insight IA et action recommandée. Traçabilité complète dans Google Sheets.
De la soumission du formulaire à l'email envoyé : moins de 30 secondes, sans intervention humaine.
Biuro Francja · Agent IA · Confidentiel3 / 12
Process Résumé — Workflow simplifié
5 nœuds n8n — de la soumission à l'action commerciale
1
2
3
4
5
⟶
⟶
⟶
⟶
Webhook
Tally
Edit Fields
(Code)
AI Agent
GPT-4.1
Parse &
Merge
Routing &
Actions
POST /prospect
Reçoit données Tally
en temps réel
resolveField()
findByLabel()
Email professionnel check
Prompt calibré
Score 0-65
JSON structuré strict
JSON parse
Try/catch fallback
Merge lead + score
If HOT / WARM / COLD
Gmail + Sheets
Log systématique
Routing Logic — 3 branches + log systématique
HOT — Score ≥ 80
Email prospect A + Alerte interne
→ Appel sous 24h
WARM — Score 50-79
Email prospect B + Alerte interne
→ Nurture relance J+3
COLD — Score < 50
NoOp — Log seulement
→ Aucune action
Tous les leads
Append row Google Sheets
→ Historique complet
Biuro Francja · Agent IA · Confidentiel4 / 12
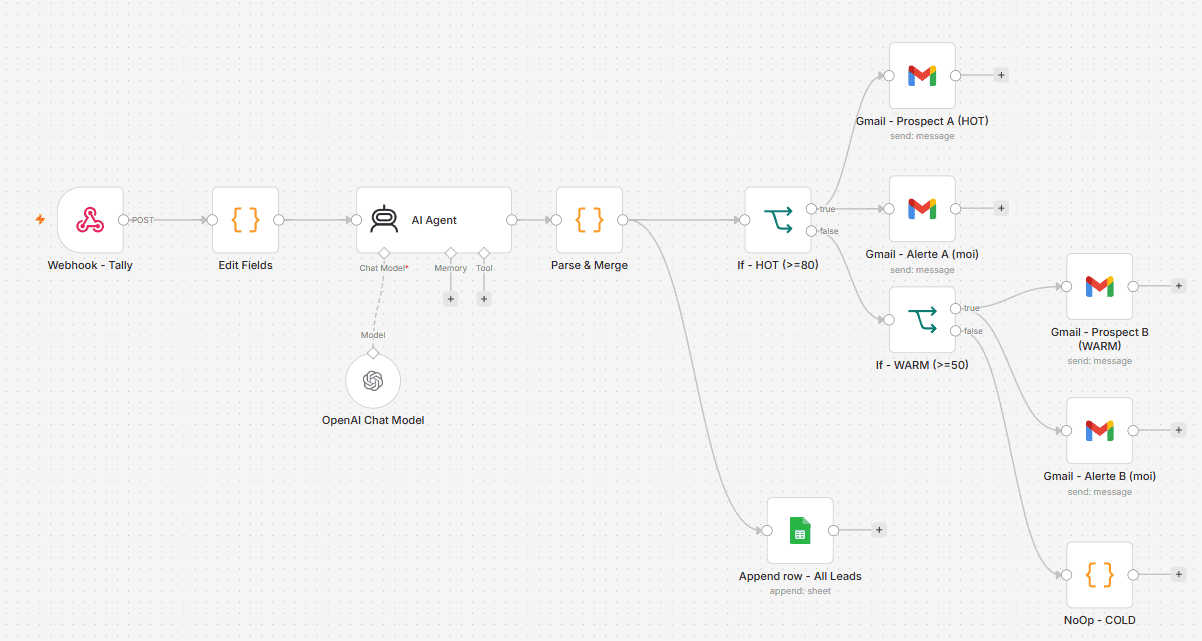
Architecture Workflow
Vue réelle du workflow dans n8n — 12 nœuds connectés
PIPELINE PRINCIPAL
Webhook Tally → Edit Fields → AI Agent → Parse & Merge → Routing
LLM CONNECTÉ
OpenAI Chat Model rattaché à l'AI Agent via le port ai_languageModel
3 BRANCHES ROUTING
HOT (Gmail x2) · WARM (Gmail x2) · COLD (NoOp)
LOG SYSTÉMATIQUE
Tous les leads sont enregistrés dans Google Sheets via Append row
Architecture en chiffres
12 nœuds au total · 5 nœuds pour le pipeline principal · 2 nœuds If pour le routing · 4 nœuds Gmail (2 prospects + 2 alertes) · 1 nœud Google Sheets en log systématique · 1 NoOp pour les leads COLD
Biuro Francja · Agent IA · Confidentiel5 / 12
Critère 1 — Bénéfices, Risques & Évolutions
Vision équilibrée du projet
Gain de temps : ~20 min → <30 sec par lead
Priorisation objective et reproductible
Scoring calibré sur expertise métier réelle
Communication automatisée et personnalisée
Traçabilité complète dans Google Sheets
Scalable : 10 ou 1000 leads, même coût
Pas de scraping = pas de dépendance aux sites
Dépendance OpenAI (coût, disponibilité API)
Hallucinations si données formulaire pauvres
Formulaire mal rempli → scoring biaisé
Coût API à monitorer si volume élevé
Maintenance prompt si marché évolue
Score max 65/100 sans analyse de site web
Pas de CRM intégré nativement (Phase 2)
Ajout scraping optionnel (score max 100)
CRM natif (HubSpot / Pipedrive)
Notification Slack / Telegram temps réel
Enrichissement LinkedIn (Phantombuster)
Agent follow-up conversationnel auto
Dashboard scoring temps réel
Extension marchés (DE, BE, ES)
Mitigation des risques
Fallback parsing robuste (try/catch → score 0, tier C) · Instructions strictes : « Do NOT invent information » · Temperature 0.2 · Score plafonné 65 sans scraping · Mode test avec 3 profils validés
Biuro Francja · Agent IA · Confidentiel6 / 12
Critère 2 — Contrôle Qualité
Testé, données fiables, stack justifié
Workflow sans scraping validéPipeline simplifié — résultats stables et reproductibles en <3 sec
3 profils de test définisHOT (~60/65) · WARM (~45/65) · COLD (~15/65) — cURL documentés
Parsing Tally robusteresolveField() gère string, array d'IDs, object, null — zéro crash
Recherche champs par labelfindByLabel() insensible à la casse + fallback par index
Fallback JSON parsingTry/catch sur output IA → score:0 + tier:C si JSON invalide
Détection email professionnelGmail, wp.pl, o2.pl, onet.pl détectés → flag is_professional_email
site_accessible = false transmis à l'IADigital readiness et international signals forcés à 0
n8n
Open-source, auto-hébergeable, RGPD. Code nodes pour flexibilité totale.
Tally
Formulaire no-code, webhook natif, gratuit. JSON structuré.
GPT-4.1-mini
Rapport qualité/coût optimal. Temp 0.2. ~$0.003/lead.
Gmail API
OAuth2 sécurisé, logs natifs. Pas de SMTP exposé.
G. Sheets
CRM léger zero-config. Historique auto. Accessible à l'équipe.
Pourquoi pas de scraping ?
Simplifie le pipeline, élimine les erreurs de sites inaccessibles, réduit la latence à <3 sec. Le scoring secteur + taille + email reste très discriminant.
Biuro Francja · Agent IA · Confidentiel7 / 12
Critère 3 — Prompt Engineering
Persona-based · Few-shot · Structured output · Step-by-step
"You are a B2B lead
qualification engine
for Biuro Francja —
the leading French-Polish
export consultancy
for Polish SMEs."
JustificationL'IA adopte le rôle d'expert export PL→FR. Le contexte métier guide chaque décision. Sans persona, scoring trop généraliste.
"Okna i drzwi = 35pts
Meubles = 30pts
IT/Software = 15pts
50-249 sal. = 25pts
10-49 sal. = 15pts
1-9 sal. = 5pts"
JustificationExemples calibrés par secteur et taille. Barème exact — pas d'ambiguïté, reproductibilité garantie.
"OUTPUT FORMAT
(strict JSON only):
{
score: number,
tier: A|B|C,
insight: string(FR),
recommended_action,
score_breakdown:{...}
}"
JustificationJSON strict parsé par code. Fallback try/catch si écart. Pipeline 100% automatisé.
"1. Sector (0-35)
2. Size (0-25)
3. Digital (0-20)
4. Intl (0-20)
→ Sum = final score
→ breakdown requis"
Justification4 critères indépendants justifiés séparément. Transparence totale du scoring.
Règle critique : "Do NOT invent information. Base your score ONLY on data provided. Be STRICT: if no evidence, award 0 points."
Biuro Francja · Agent IA · Confidentiel8 / 12
Critère 3 — Itérations du Prompt
De la V1 naïve à la V4 production — chaque itération résout un problème réel
V1Prompt naïf
"Analyze this company
and give a score."
Problème identifié
Score inventé, aucun barème. Réponse en texte libre — impossible à parser.
Baseline
Référence pour mesurer chaque amélioration successive.
⟶
V2+ Persona & Barème
"You are a B2B engine
for Biuro Francja.
Okna = 35pts
50-249 sal. = 25pts"
Problème restant
L'IA invente des données quand l'information manque. Output texte libre.
Correction appliquée
Persona expert + barème explicite. Scoring devenu cohérent.
⟶
V3+ JSON strict
"OUTPUT: strict JSON
no markdown outside.
Do NOT invent data.
site_accessible=false"
Problème restant
JSON parfois encadré de balises markdown. Parsing échoue.
Correction appliquée
JSON strict + anti-hallucination + flag site_accessible transmis.
⟶
V4Production
"score_breakdown: {
market_fit: 0-35
company_size: 0-25
digital: 0-20
intl_signals: 0-20
}"
Stable en production
Score reproductible, parsing robuste, zéro hallucination en test.
Déployé
Temp 0.2, fallback try/catch, score_breakdown pour transparence.
Biuro Francja · Agent IA · Confidentiel9 / 12
Critère 4 — Diffusion & Adoption
Intégration dans le quotidien de Biuro Francja
Parcours utilisateur — De la soumission à l'action commerciale
1
PME Polonaise
Formulaire Tally
2 minutes
⟶
2
Webhook n8n
Données reçues
instantanément
⟶
3
Agent IA score
Scoring automatique
~3 secondes
⟶
4
Emails envoyés
Prospect + alerte
personnalisés
⟶
5
Action commerciale
HOT : appel 24h
WARM : nurture J+3
- Zéro formation — aucun nouvel outil
- Alerte dans la boîte email existante
- Google Sheets familier pour le suivi
- Dashboard prévu Phase 2
- Formulaire Tally partageable (lien / QR)
- Email prospect auto et personnalisé
- Branding Biuro Francja dans chaque email
- Calendly intégré — conversion directe
- Coût marginal ~$0.003 par lead
- Volume illimité — même workflow
- Multi-marchés : DE, BE, ES (Phase 3)
- API n8n — intégration CRM future
Biuro Francja · Agent IA · Confidentiel10 / 12
Résultats & Métriques
Ce que le système produit — version sans scraping
< 3s
Traitement complet
d'un lead
0
Intervention
humaine requise
65 pts
Score maximum
sans scraping
3
Tiers de routing
HOT / WARM / COLD
~$0.003
Coût par lead
GPT-4.1-mini
Critère
Poids
HOT
WARM
COLD
Market Fit (secteur)
0–35
Okna i drzwi → 35
Meubles → 30
Other B2B → 10
Company Size (taille)
0–25
50-249 sal. → 25
10-49 sal. → 15
1-9 sal. → 5
Digital Readiness
0–20
= 0 pts — pas de scraping dans cette version
International Signals
0–20
Email pro → 5
Email pro → 5
Gmail → 0
TOTAL (max sans scraping)
0–65
~60-65 → Tier B
~45-50 → Tier B/C
~10-15 → Tier C
Note
Sans scraping, le score maximum est 65/100. Le scoring reste très discriminant grâce au poids combiné du secteur (35 pts) et de la taille (25 pts). L'ajout du scraping en Phase 2 activera Digital Readiness et International Signals pour un score complet sur 100.
Biuro Francja · Agent IA · Confidentiel11 / 12
Vision & Next Steps
Biuro Francja — Roadmap Agent IA
- Webhook Tally → n8n opérationnel
- Parsing robuste (resolveField)
- Scoring IA 3 critères calibré
- Routing HOT/WARM/COLD automatique
- Emails personnalisés envoyés
- Logs Google Sheets actifs
- 3 profils de test validés
PHASE 2
Court terme — 3 mois
- Ajout scraping optionnel (score 100)
- Enrichissement LinkedIn automatique
- Notification Slack temps réel
- Dashboard scoring (Metabase)
- A/B test emails — taux d'ouverture
- Ajustement seuils Tier
PHASE 3
Moyen terme — 6-12 mois
- Intégration CRM (HubSpot)
- Agent follow-up conversationnel
- Extension marchés DE, BE, ES
- Fine-tuning sur données réelles
- API Biuro Francja (SaaS futur)
« L'agent IA ne remplace pas l'entrepreneur — il lui donne le pouvoir de consacrer son énergie aux prospects qui méritent vraiment son temps. »
— Biuro Francja, 2026
Biuro Francja · Agent IA · Confidentiel12 / 12